Reading: https://substack.com/home/post/p-152106163, https://substack.com/@chipstrat
ASIC vs SOC, which is more optimal for my use case?
Edge stuff:
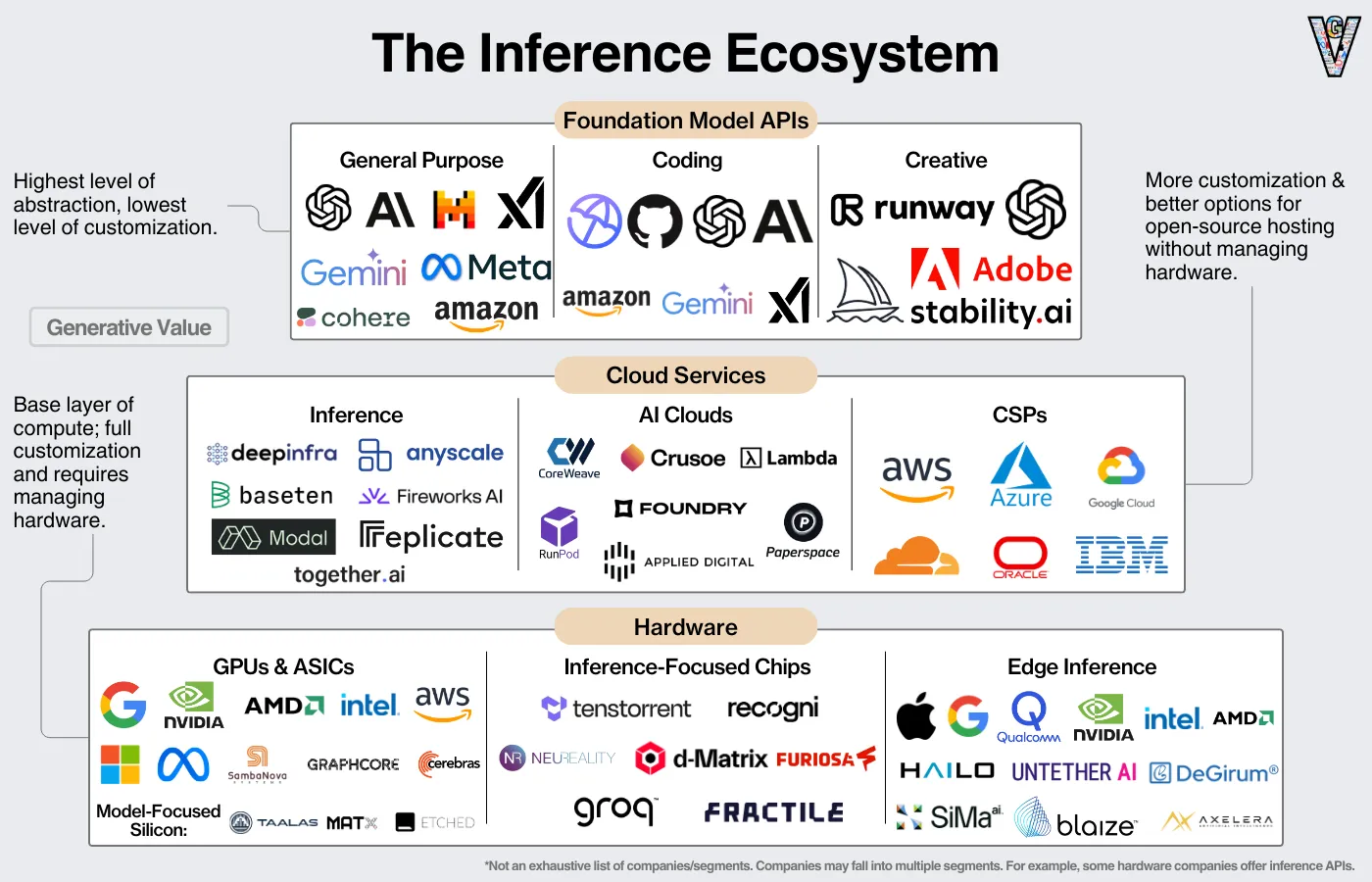
Quick summary from Claude: Let me break down what each of the edge inference companies shown in the image would specialize in for edge AI deployment:
Apple: Focuses on running AI models directly on iPhones, iPads, and other Apple devices, optimizing for their custom silicon (like the Neural Engine in their chips) to run AI workloads efficiently while maintaining privacy.
Google: Specializes in running TensorFlow Lite models on mobile and IoT devices, with specific optimizations for Android devices and their Edge TPU architecture.
Qualcomm: Leverages their Snapdragon platforms and Neural Processing Units (NPUs) to run AI models on mobile devices, especially Android phones, with their AI Engine SDK.
NVIDIA: Provides Jetson platforms and TensorRT optimization software for running AI models on edge devices, particularly strong in computer vision applications.
Intel: Offers OpenVINO toolkit for optimizing and deploying AI models on their hardware, including CPUs and their Movidius vision processing units (VPUs).
AMD: Provides tools and solutions for running AI models on their CPUs and GPUs in edge devices, with specific optimizations for their hardware architecture.
Hailo: Creates specialized AI processors and software tools specifically designed for edge devices, focusing on high performance with low power consumption.
Untether AI: Develops at-memory computation architecture for AI acceleration at the edge, optimizing for both speed and energy efficiency.
DeGirum: Offers solutions for optimizing and deploying AI models on various edge devices with their software stack.
SiMa.ai: Provides purpose-built MLSoC (Machine Learning System-on-Chip) platform for embedded edge applications.
Blaize: Creates Graph Streaming Processor (GSP) architecture specifically for AI workloads at the edge, with their own software stack.
Axelera: Develops AI acceleration solutions focused on power-efficient edge deployment, particularly for industrial and IoT applications.
The key themes across these companies are:
- Hardware optimization for AI workloads
- Power efficiency for battery-operated devices
- Model compression and optimization
- Support for real-time processing
- Focus on specific use cases like computer vision, natural language processing, or sensor data analysis
At first glance, Untether AI and Hailo seem to be what Im looking for, jk idk what they do
Hailo -> specialized AI accelerators and vision processors What do they exactly do and what is the advantage of them over others?
On a side note: Edge inference and cloud inference, doing both possible? with latter a user opt. Let me break down AI accelerators and vision processors within ASICs systematically:
AI Accelerators:
- These are specialized circuits designed to speed up AI/ML computations, particularly matrix multiplications and convolutions
- They typically include:
- Multiple Processing Elements (PEs) that perform parallel computations
- Local memory/buffers to store weights and activations
- Custom datapaths optimized for AI operations
- Specialized arithmetic units (often using lower precision like INT8 or FP16)
Vision Processors:
- Specialized circuits focused on image/video processing and computer vision tasks
- Key components include:
- Image Signal Processors (ISP) for raw sensor data processing
- Vector processing units for pixel operations
- Dedicated hardware for common CV operations (filtering, feature detection)
- Hardware-accelerated video codecs
Integration within an ASIC:
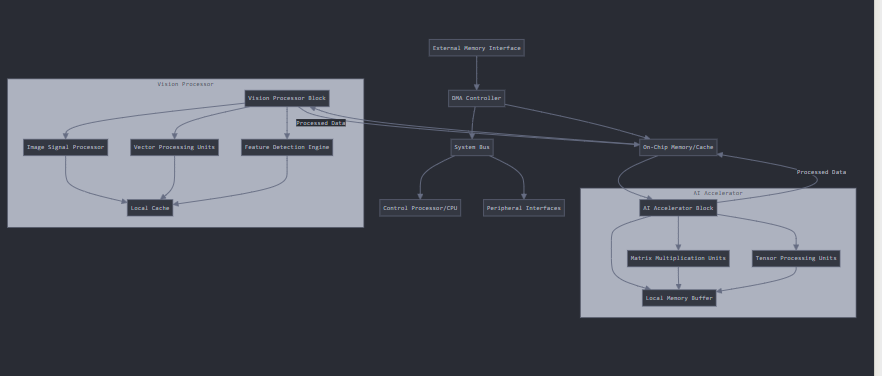
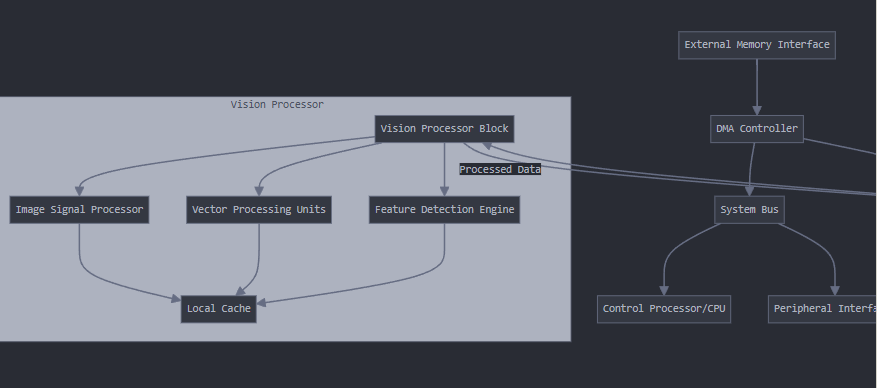
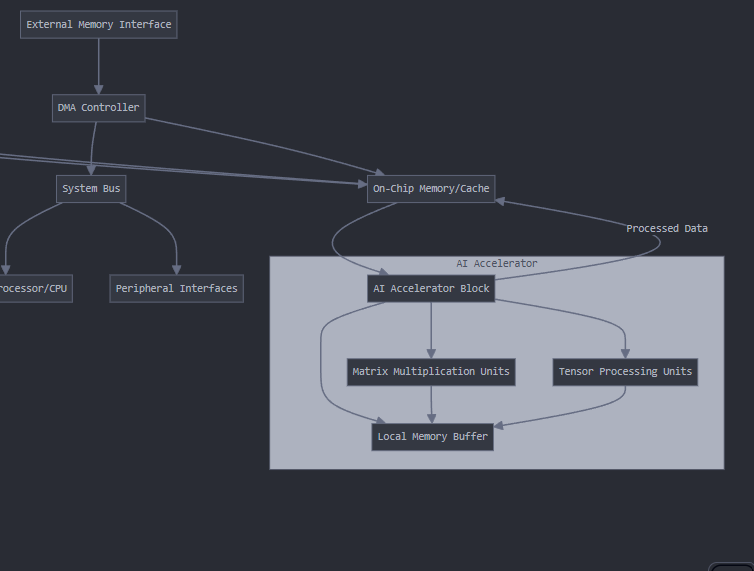
Key aspects of this integration:
- Data Flow
- Input data comes through external memory interface
- DMA controller manages data movement between components
- Local memory buffers minimize external memory access
- Results flow back through the system bus to output or storage
- Processing Pipeline
- Vision processor often processes raw data first
- Results feed into AI accelerator for inference
- Control processor orchestrates the flow
- Both blocks can work in parallel for efficiency
- Memory Hierarchy
- External DRAM for bulk storage
- On-chip SRAM for fast access
- Local buffers within each block
- Cache hierarchy for frequently accessed data
- Optimization Techniques:
- Data reuse to minimize memory access
- Pipeline parallelism between blocks
- Custom datapaths for common operations
- Clock and power gating for unused blocks
- Common Challenges:
- Memory bandwidth bottlenecks
- Power consumption management
- Thermal considerations
- Balancing flexibility vs. efficiency
This architecture allows for efficient processing of AI and vision workloads while maintaining flexibility for different applications. The exact configuration would depend on the specific use case requirements for power, performance, and area constraints. ||Claude
NPU stuff: https://www.chipstrat.com/p/the-circuit-episode-70-npus